After reviewing over 50 AI-built codebases this year, a pattern has emerged. Every founder who walks through our door falls into one of three categories. Each one teaches the same lesson – but at very different price points.
The first founder
They built an MVP on Lovable or Replit. It worked. Users signed up. Revenue started coming in. The UI was polished, the features were solid, and by every visible measure the product was ready to scale.
Then they tried to hire a developer. The developer opened the codebase, spent two hours reading it, and said: “I’d rather start over than maintain this.”
The founder thinks the developer is being dramatic. The developer is not being dramatic.
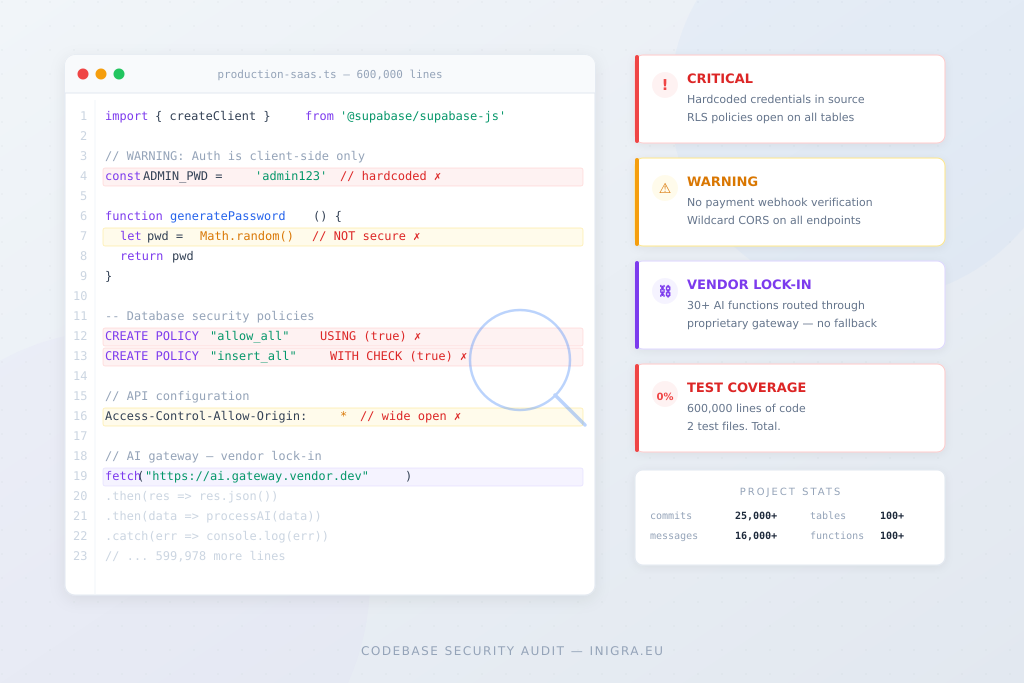
What we find when we audit these codebases is always the same: database security policies wide open, no payment verification on Stripe webhooks, every API endpoint accepting requests from any website on the internet, credentials hardcoded in the source, and zero tests for the entire application. The AI built what the founder asked for. It didn’t build what the founder didn’t know to ask for.
The rescue costs more than the original build. Always. Because now they’re paying to understand what exists, undo what’s broken, and rebuild what should have been done right from the start – all while keeping a live product running for paying users.
The second founder
They chased a low hourly rate. Found a team quoting $15-20/hr. The proposal looked good. The timeline was aggressive. The first demo was impressive.
Then things started slipping. Deadlines moved. Features that “worked” in the demo broke in production. Bug fixes introduced new bugs. The codebase grew but the product didn’t improve. Communication became a game of managing expectations rather than building software.
When we open these codebases, we find something that looks like a Ferrari on the outside but has a lawnmower engine inside. The architecture doesn’t support the features. The code is copy-pasted across files with slight variations. There’s no consistent error handling, no logging, no deployment pipeline. It’s cheaper to delete the repo and start over than to fix what’s there.
The second founder ends up paying twice: once for the version that doesn’t work, and once for the version that does.
The third founder
They come to us first. They have a patent, or a validated idea, or an angel investor. They’ve done their homework. They know that building software is an investment, not an expense, and they want it done right the first time.
They don’t ask “how cheap can you build this?” They ask “what should we build first, and how do we make sure it’s production-ready?”
These founders get the same senior engineers and the same AI-assisted development tools as everyone else. The difference is that everything is built with intention from day one: proper security policies, payment verification, test coverage, clean architecture, and zero vendor lock-in. When they hire a CTO six months later, the CTO opens the repo and says “this is solid – let’s build on it.”
The strategic founder typically spends less than the first two combined.
The numbers
Here’s what we see across our projects:
The first founder pays £8,000-20,000 to fix and migrate an AI-built codebase that originally cost £200 in platform credits.
The second founder pays £15,000-30,000 for a proper rebuild after spending £10,000-20,000 on the version that didn’t work. Total cost: £25,000-50,000.
The third founder pays £10,000-25,000 once, for a production-ready product they own completely.
What changed in 2026
Two years ago, building an MVP with a senior development team cost £30,000-50,000 and took 4-6 months. The “build it cheap” approach made economic sense even with the risks, because the alternative was genuinely expensive.
In 2026, senior developers using AI-assisted coding tools deliver 2-3x faster than they did in 2024. A production-ready MVP that would have cost £40,000 two years ago now costs £10,000-20,000 and ships in 6-8 weeks. The gap between “cheap and risky” and “proper and reliable” has collapsed.
The strategic approach is no longer the expensive option. It’s the only option that makes financial sense.
Which founder are you?
If you’re already the first or second founder, it’s not too late. A codebase audit takes 2-3 days and tells you exactly what you have, what needs fixing, and what it costs. Sometimes the news is better than expected. Sometimes it confirms what you already suspected. Either way, you stop guessing and start making informed decisions.
If you haven’t started building yet, you have the chance to be the third founder. Come to us with your idea, your validation, and your budget. We’ll tell you honestly what to build first and what to leave for later.
We’re a senior EU-based team. Google Cloud Partner. 5.0 on Clutch. MVPs from £10,000.
Book a free discovery call. No pressure, no pitch. Just a straight answer about what it would take to build your product right.
We build MVPs and rescue AI-built apps at Inigra. If you want to see what we find inside AI-generated codebases, read our 600K line audit.